雜訊: 人類判斷的缺陷這本書由一群學者聯手撰寫, 包括諾貝爾經濟學獎得主丹尼爾‧康納曼(Daniel Kahneman), 巴黎高等商學院教授奧利維‧席波尼(Olivier Sibony)與哈佛法學教授凱斯‧桑思汀(Cass R. Sunstein). 廣義來說, 康納曼(快思慢想作者)聯合這二位作者從心理, 統計, 管理與法律各個角度, 把焦點放在我們做判斷時會遇到的雜訊.
我們常常對同一件事情有不同的判斷. 例如: 不同醫師對同一個病人的病情, 法官們對同一案件的裁決等等. 原因是判斷過程有了分歧, 而造成不同的結果. 作者告訴我們會影響判斷過程的因子是由偏差(bias)與雜訊(noise)兩部分組成. 並定義二者差異:偏誤是系統性的, 偏差有一致性, 而雜訊則是隨機的. 下面是書中的範例, 應該從此範例中會有個概念.
有四隊, 每一隊有五人;同一隊的人共用一支步槍,每人發射一槍。圖1顯示各隊的結果
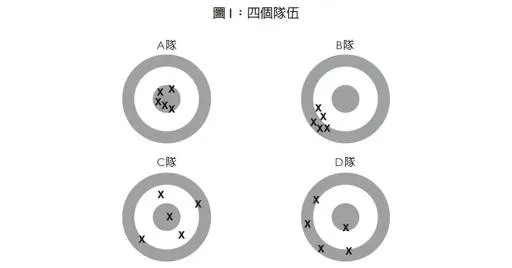
A隊是最接近理想的一隊, 這一隊的彈著點都落在靶心上, 而且聚集在一起, 幾乎是一個完美的模式.
B隊則有偏差(biased), 因為這五發都沒射中靶心, 而且都偏到同一個角落.
C隊有雜訊(noise), 因為彈著點很分散. 由於彈著點幾乎都在靶心四周,但沒有明顯偏誤.
D隊則既有偏差, 又有雜訊. 他們跟B隊一樣, 彈著點偏向一側, 落點也和C隊一樣分散.
從這個範例可以知道, 如果所有判斷都一致性的偏高或偏低, 即為偏差; 而在相同情境做出判斷時沒有一致性, 就是雜訊.
作者丹尼爾先生在”快思慢想”書中, 已經探討了許多我們處理問題時, 有哪些心理及生理上的反應或行為會影響我們做判斷時的偏差. 所以本書重點放在雜訊產生的原因與減少雜訊的方法上, 嘗試幫助我們減少判斷過程時的雜訊, 提昇判斷品質. 我也因爲這本書學到在判斷過程中, 可以有哪些不同視角和方法來協助判斷.
識別雜訊
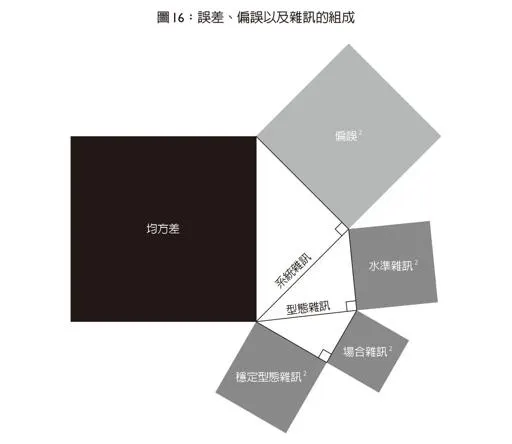
作者將判斷時會發生的整體誤差, 稱為系統誤差, 而系統誤差就是由剛剛所提的偏差與雜訊所帶來的. 那如何測量偏差與雜訊對系統誤差影響的比例? 作者利用高斯的均方差(MSE)做測量. 我們可以將誤差用以下方程式表示之.
系統誤差(均方差)=偏差²+系統雜訊²
為什麼不直接以 系統誤差=偏差+系統雜訊 來表示,
因為當系統誤差大於偏差時, 系統雜訊為正值, 系統誤差小於偏差時, 系統雜訊為負值. 有誤差就是有誤差, 避免正負誤差互相抵銷或是零的情形.
進一步拆解系統雜訊, 它是由水準雜訊與型態雜訊所組成. 書中定義如下:
系統雜訊: 同個案件出現不同的判斷
水準雜訊(level error): 不同判斷者個別的傾向差異, 例如: 同一件事, 有的人樂觀, 有的人悲觀. 同一個案件, 有些法官判得相對重, 有些是好人法官.
型態雜訊(pattern noise): 水準雜訊是說同一件事, 不同人的觀感. 那型態雜訊說的就是同一個人對不同事件時的判斷不一致. 例如, 有些主管對每日工作時數很在乎, 有些主管認為效率是重要的.由於這種型態的雜訊是每個判斷者長期以來的觀點, 所以歸納成穩定型態雜訊. 既然有穩定型態雜訊, 那暫時型態雜訊來源為場合雜訊: 法官心情是否影響審判, NBA 球員在主客場的表現, 主管偏好某幾所大學等等.
型態雜訊²=穩定型態雜訊²+暫時(場合)雜訊²
同樣的, 系統雜訊可以用方程式表示為:
系統雜訊²=水準雜訊²+型態雜訊²
我們以下圖來看, 就像我們學的畢式定理. 所以偏差和雜訊在誤差方程式中扮演同樣的角色. 兩者是互相獨立的,就總體誤差而言,兩者的權重也相等. 我們也可以歸納出:
- 系統誤差由偏差和系統雜訊組成
- 系統雜訊可以拆解為水準雜訊和型態雜訊
- 型態雜訊可以拆解為穩定型態雜訊和場合雜訊
MSE 本質上還是結果導向的工具, MSE 方法確實一樣用歷史資料在計算,停留在結果層面,沒進到過程審查. 這就是書中警告的風險:
所以, 作者提出了一個決策保健(decision hygiene)的策略:
- 把複雜決策分成幾個獨立的子問題, 逐一評估, 而不是做整體直覺式評分, 避免某個早期印象影響後面所有看法, 必要時引入客觀工具或準則(例如評分表, 檢查清單)來標準化流程
- 避免太早下結論, 遺漏跟結論不一致的訊息.
- 使用演算法輔助, 在預測性判斷中,簡單模型(如權重模型)往往不受人類情緒、疲勞等因素影響.
- 邀請多個判斷者, 並讓判斷者各自獨立給出意見, 再做整合判斷. 盡量避免判斷受到討論氛圍或社群壓力影響.
- 盡量找尋外部標準與相似案例比較, 而不是只靠當下直覺. 就如作者所說, 判斷的目的不是要求完美但要精準.
提升判斷的品質
大多數的人認為有經驗的人所做的判斷會比較正確. 但事實上, 做出一個正確的判斷是非常困難的, 因為判斷會因為你的喜好, 個性等等外在因素影響. 舉個書中例子來說, 假設某人被指控犯了罪,該案件的判決結果可能會因為?被指派到的法官因為心情好壞, 案件多寡, 甚至於法官喜歡的球隊在前一天是輸是贏被影響.
“太陽明天升起”或”水的化學式是H2O”這是事實並不屬於判斷, 真正屬於需要判斷的事會介於事實與經驗之間, 答案具有不確定性, 不是由個人喜好品味決定, 判斷過程中需要邏輯或數據基礎.
書中提供了兩種不同的方法對判斷做評估: 一種是比較判斷與實際結果的差異(事後才知道準確度), 另一種則是評估做出判斷的過程. 只看判斷結果, 風險較高, 作者用通膨預測舉例:就算是一個非常專業、嚴謹的經濟分析師,已經用上所有資料和模型,預測下一季通膨率時還是可能預測錯;反過來說,一隻「亂丟飛鏢的黑猩猩」偶爾也可能剛好射到正確數字. 與評估判斷的過程比較起來, 只依靠結果來評估判斷能力是有風險的. 更何況是單一次性判斷, 例如當時疫情指揮中心開放COVID-19是否開放入境. 所以作者告訴我們, 評估判斷的準確性, 應該著眼於過程, 你的資料或資訊是否正確, 分析方法是否嚴謹、程序合理、可重複利用.
接著, 書中區分有二種判斷型態: 預測性判斷和評估性判斷. 預測性判斷可計算, 利用模型及演算法評估的是”未來或未知的結果會怎樣”. 這類判斷有個特點: 客觀, 符合邏輯及概率. 評估性判斷則不同, 它處理的是價值與效益, 而不是客觀答案, 書中有一個很實際的例子, 假設一位軍事指揮官要不要下令攻擊。第一階段,他需要的是預測性判斷, 敵軍戰力有多高?反擊風險多大?平民傷亡機率?這些是可估算、可建模、可用情報資料支持的預測。第二階段,它才會進入評估性判斷:就算成功,我們願不願意承擔那個代價?短期的戰果值不值得長期的效益? 這兩種判斷不能混在一起,因為前者追求客觀準確,後者則是效益選擇與附加風險. 我相信大家常常在工作上都會在這二種判斷模式上切換.
過程比結果更重要
我想, 這本書主要想跟我們說的是人腦天生就不是客觀的判斷機器. 就如書中有個例子就說到: 同樣四個形容詞, ”聰明、頑強、機巧、沒原則”出現在履歷表中的評價, 如果把順序反過來”沒原則、機巧、頑強、聰明” 它可能就會影響你的決定.作者最終目的也不是要做到完美判斷, 而是在做出判斷前建立可重複利用的審查流程. 作者用體重計做了很好的比喻: 如果你知道家裡的體重計永遠多0.2 公斤, 你可以有兩種處理方式. 第一種, 是每次量完都手動扣 0.2, 這是事後修正. 第二種, 是直接把體重計校正, 讓它之後都比較準, 這是事前預防. 回到原點, 採用作者所提的決策保健策略讓判斷過程藉由工具, 團體, 證據及長時間的回饋校正來減少因人事時地物所產生的誤差而影響判斷結果.
我們無法完全消除雜訊,但可以透過科學的方法與管理,將其控制在可接受的範圍內.