談談以文字生成圖
目前輸入文字生成圖像主要生成的作法, 不是利用像素接龍(Autoregressive:一次一個像素依序的生成).
使用像素(pixel) 一個接著一個生成的方式會出現那些問題? 而哪些又是目前GAI文字生成圖像的主要模型呢? 重點摘要如下:

生成的方法
生成式人工智慧(GAI)是找出對的AI模型輔以好的資料訓練, 最終將你想呈現的, 透過文字輸入來產生不同的內容(如撰寫報告, 圖像生成、音樂生成). 而內容生成的基本單位會有所不同.
輸入文字, 生成文字(例如: 報告, 文案)
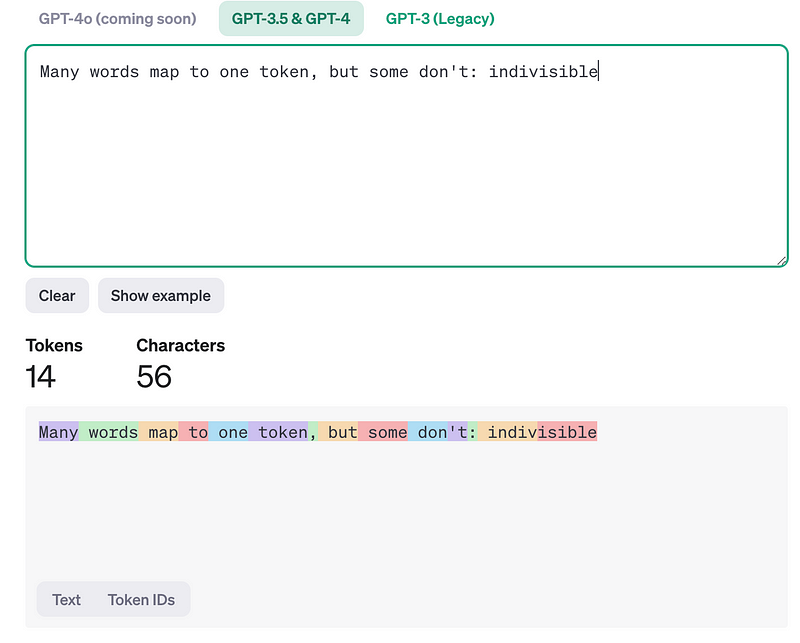
中文: 是以字(token)為單位
英文:這些App都會提供他們計算token的規則(Tokenizer). 我以ChatGPT提供的工具來舉例. 有一個單字就是一個token, 也有些是分割.
每一個token用不同顏色(空格, 標點符號也算)
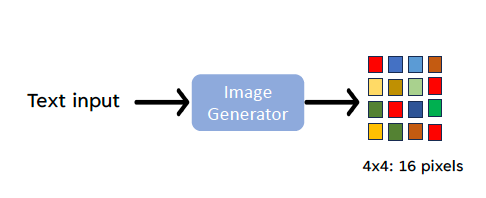
輸入文字, 生成圖像: 以像素(pixel)為單位
Example: 4×4: 16 pixels

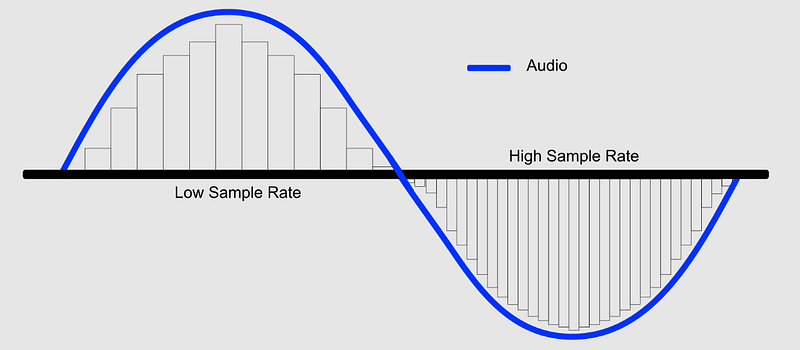
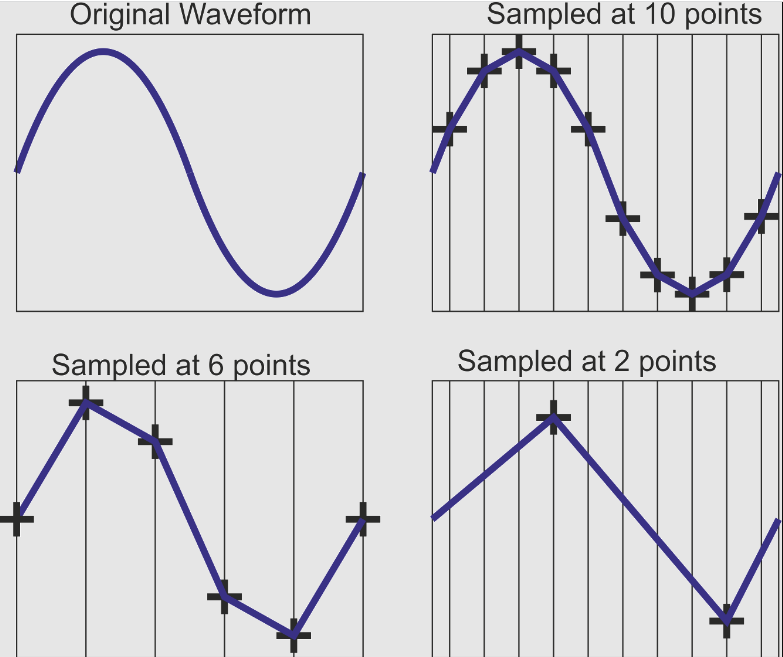
輸入文字, 生成聲音: 以取樣率(sampling rate)為單位
回到今天主題, 輸入文字生成圖片. 有二種基本方法 Autoregressive, Non-Autogressive 生成圖片.
- Autoregressive方式生成圖片的概念: 一次一個像素產生, 每個像素生成會依據機率高低及所輸入文字來生成下個像素.
優點: 品質好, 缺點: 耗費時間.
範例:OpenAI 在2020年發表的 Image GPT, 下圖是Image GPT使用autoregressive 的方法訓練生成圖像AI 模型的過程.
- 輸入一張照片(訓練資料)
- 轉換成低解析度(二維)
- 拉成一個序列(sequence)
- 一個接著一個像素(模仿文字生成)的方式來訓練 (越靠近目標越好)
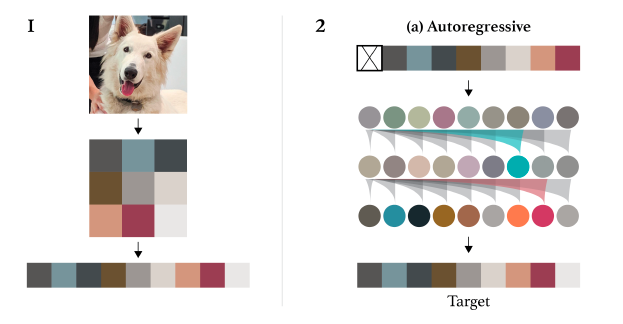
像素是一行一行生成出來的.

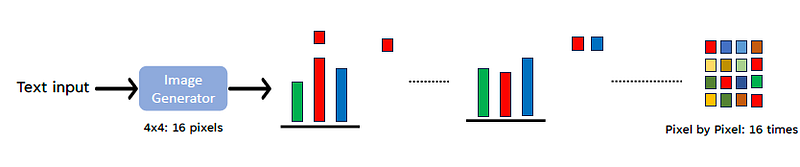
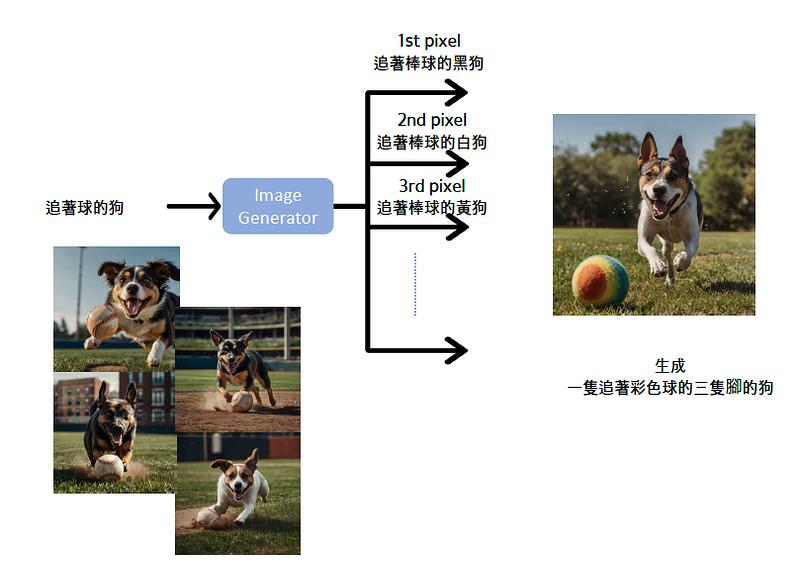
一次就畫完一張圖? 答案是可以的. 這種方法是 Non-Autoregressive: 每個像素同時生成, 因為現在computing power 足以應付所需算力.
優點: 速度快, 缺點: 計算成本高, 品質較差(後面會解釋).
為什麼一次生成品質會差? 因為一張圖的生成有太多種可能性, 無法完全用文字形容你想要的那張圖. 所以每個像素需同時畫出時, 每個像素生成不會有一致性的方向. 造成每個pixel會以不同方向去生成而造成圖像有不連貫之情形產生. 如下面範例, 生成一幀奇怪的圖.
Autoregressive 與 Non-autoregressive 模型之比較表

Note: 兼顧品質與時效, 現在有很多研究方向朝AR and NAR合併使用(先以AR生成大方向, 再輔以NAR快速生成整張圖).
更深入討論生成式AI圖像生成模型之前, 回顧下訓練方式.
輸入的文字(條件式)跟對應的圖配對訓練
範例:

為了要解決輸入文字後, 同時生成圖像時所發生各個像素生成方向不一致的問題. 所以在訓練時, 同時訓練二個模型. 一個是原本生成圖像的模型, 另一個是擷取圖片特徵模型.
在圖像生成時, 圖像生成得模型是無法單靠輸入文字就產生圖像, 所以 “Encoder” 模型的目的是找出輸入文字內所涵蓋到的重要特徵, 然後輸入到圖像生成. 圖像生成模型又稱作”Decoder”, 特徵擷取模型又稱作”Encoder”.
訓練的目的是輸入跟輸出的照片盡越像越好.

在推論時, 如果輸入的文字沒有特別輸入一些需要的額外特徵, 那”額外的資訊”就會隨機給定到每一個pixel, 讓所有pixel在生成時有一樣的資訊來生成圖像.
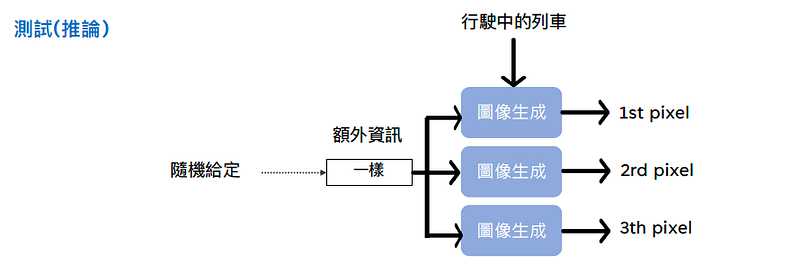
常用的模型?
VAE (Variational Auto-encoder):
- 訓練時, 從常態分配的樣本中, 取樣出一個向量並輸入給decoder.
- 訓練這個decoder能生成貓頭鷹圖片.
- 但光靠此decoder是無法對應生成的貓頭鷹圖片.
- 同時訓練一encoder, 讓此encoder可以輸入一圖片, 產生一常態分配的向量.
- 將encoder和decoder串在一起, 讓這一張圖片經過此encoder/decoder所生成的圖片越接近越好.
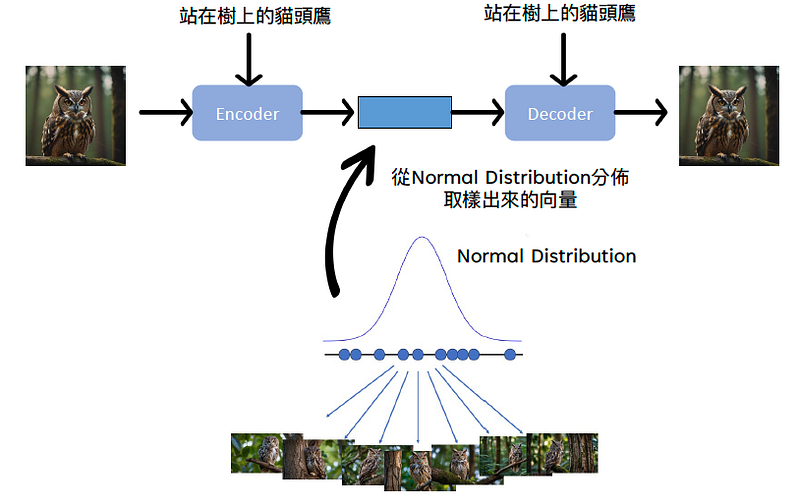
VAE缺點: 從上圖可以得知在VAE encoder是將圖像裏資訊擷取出來後, 再餵給decoder. 但這種方法
- 需要同時訓練二個模型.
- 且經過encoder/decoder二道程序, 圖像的資訊會有缺失.
Flow-based: 訓練一個模型是可逆函數, 因為此函數是可逆, 只需要訓練一個模型就好. 所以, Flow-based的處理程序就是訓練一個encoder, 輸入一張圖片而輸出一個與輸入圖相同大小的向量(256×256 pixels, 因為最後輸出一定要是可逆函數), 而這個輸出的向量要為常態分佈且這個向量能夠盡可能的對映原本訓練的圖片樣本(Maximum likelihood), 再輸出給生成圖像的encoder的逆函數 (F-1(x)).
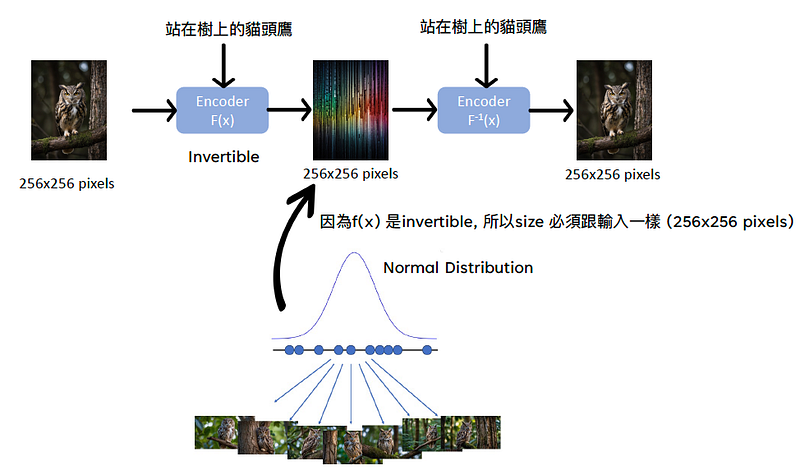
由於Flow-based是考慮到圖片之完整像素並訓練成可逆函數, 並使用maximum likelihood(最大可能產生這些樣本結果的模型), 模型能夠更準確地捕捉數據的複雜結構和細節, 而生成更高質量的圖像. 但輸入圖片畫質愈高時, 設計此模型難度也會提高. 每次生成需要通過多層的可逆變換, 這會增加計算時間和資源消耗.
Diffusion model: 提到訓練方式前, 先將Diffusion model生成圖的流程敘述下:
- 輸入一段文字(e.g. 站在樹上的貓頭鷹)
- 文字進入到Denoise(可以把Denoise想成Decoder, 每個Decoder的工作方式都是一樣的)
- 依序重複做denoise, 將雜訊濾掉(做n次, n的數目會依據模型不同有所增減, 一般來說>1000)
- 逐漸將雜訊濾除, 一直到生成原圖.
Denoise的過程又稱為 Reverse process
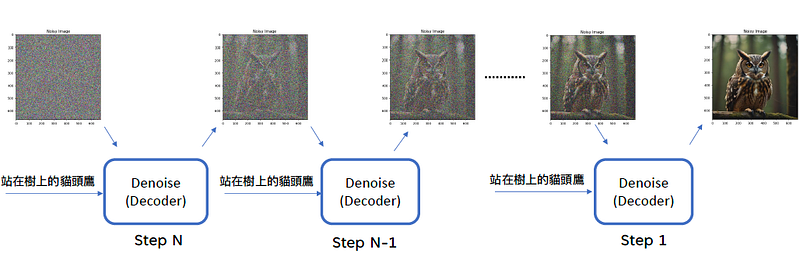
由於每次輸入的圖片雜訊狀況不一樣, “Denoise (Decoder)”如何依序濾掉雜訊? 這跟Denoise的工作原理有關.
Denoise模型除了我們輸入的文字外,模型背後會有此步驟要準備濾掉雜訊的圖片, 還有步驟次序. 於是模型中的Noise Predictor 會預測出一相對雜訊, 將背後帶入的圖片減掉此預估的雜訊輸出.而此輸出圖片就是下一步輸入之圖片.
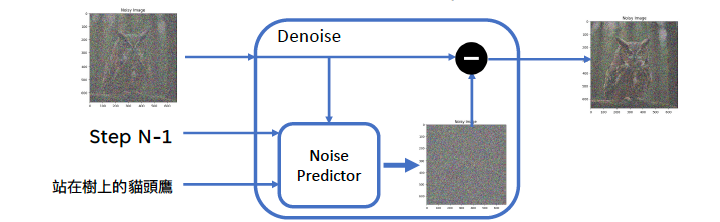
所以Difussion model, 是要訓練noise predictor, 讓它學會每一步所對應的雜訊. 這裡的問題是, 為什麼不直接訓練一個濾掉雜訊的模型就好, 而是去訓練一個noise predictor呢? 原因是設計訓練一個生成雜訊圖片的模型的困難程度比設計訓練一個圖片加上雜訊的模型簡單.
如何訓練 Noise predictor?
訓練資料是自己產生, 作法是拿一張原本的圖片再加上從normal distribution 取樣出來的雜訊就會有第一步加上雜訊的圖片, 依此類推, 再將第一步加入雜訊的圖片再加上第二次從normal distribution 取樣出來的雜訊就有第二步的結果, 這個步驟會持續到原圖看不出來為止. 這個過程叫做Forward process(Diffusion process).
訓練資料


而目前知名的輸入文字生成圖片的工具, 核心模型都是利用Difussion model. 例如:
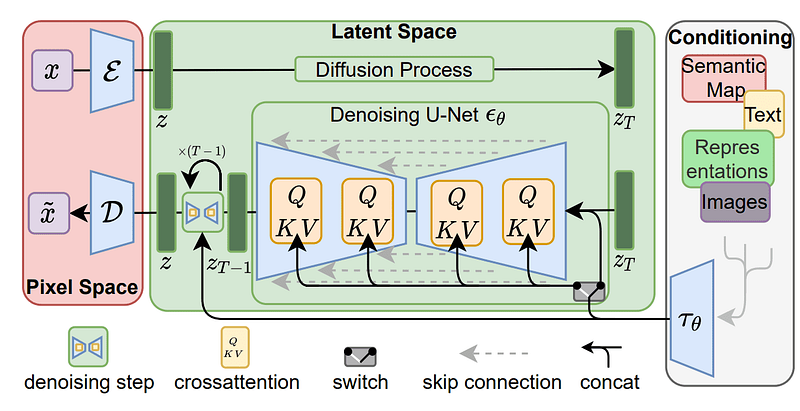
Stable Diffusion
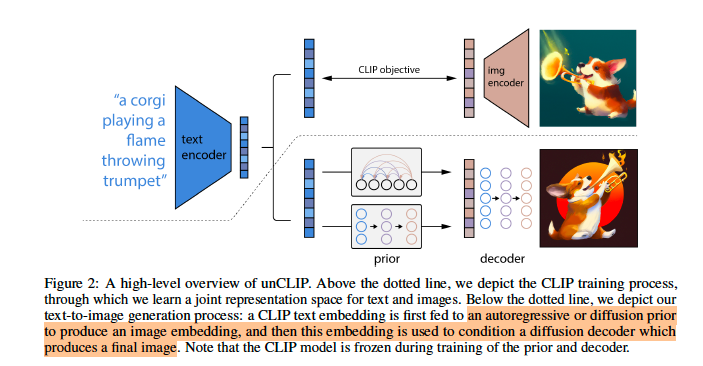
DALL-E2
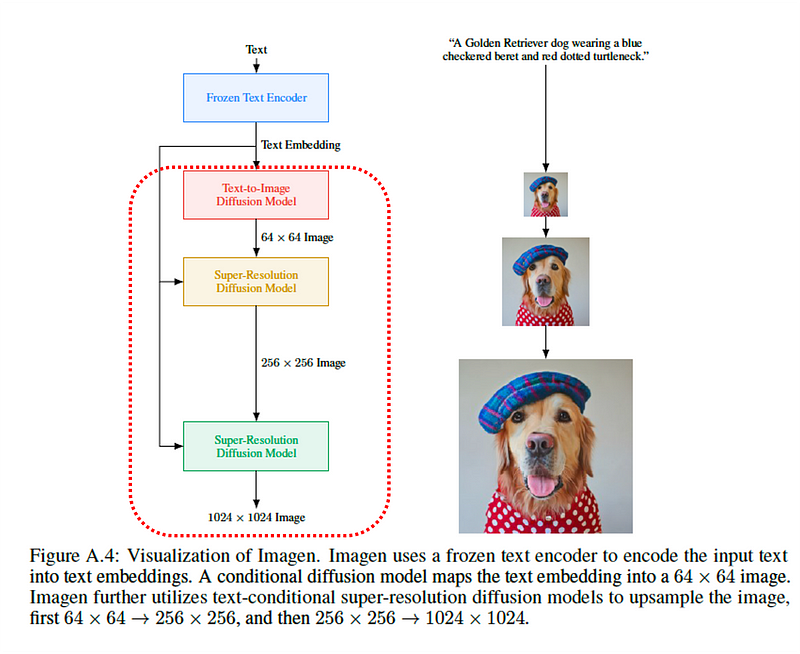
Imagen
因為Diffusion model需要多次denoise, 所以很多text to image的研究方向都是以減少denoise次數為主.